考研数据结构笔记
栈
括号匹配
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#define MAXSIZE 10
typedef struct
{
char data[MAXSIZE];
int top;
} SqStack;
// 初始化顺序栈
void initStack(SqStack *S)
{
S->top = -1;
}
// 判断是否为空
bool isEmpty(SqStack *S)
{
return S->top == -1;
}
// 判断是否满
bool isFull(SqStack *S)
{
return S->top == MAXSIZE - 1;
}
// 入栈
bool Push(SqStack *S, char *x)
{
if (isFull(S))
return false;
S->data[++S->top] = *x;
return true;
}
// 出栈
bool Pop(SqStack *S, char *x)
{
if (isEmpty(S))
return false;
*x = S->data[S->top--];
return true;
}
//检查字符串是否合法
bool checkString(char str[])
{
int length = 0;
int i = 0;
while (str[i++] != '\0')
{
length++;
}
SqStack S;
initStack(&S);
for (int i = 0; i < length; i++)
{
if (str[i] == '(' || str[i] == '{' || str[i] == '[' || str[i] == ')' || str[i] == '}' || str[i] == ']')
{
if (str[i] == '(' || str[i] == '{' || str[i] == '[')
Push(&S, &str[i]);
else
{
if (isEmpty(&S))
return false; // 匹配到右括号且栈空,不合法
char topElem;
Pop(&S, &topElem);
if (str[i] == ')' && topElem != '(')
return false;
if (str[i] == '}' && topElem != '{')
return false;
if (str[i] == ']' && topElem != '[')
return false;
}
}
}
return isEmpty(&S);
}
char a[10] = "(你好){}";
void main()
{
if (checkString(a))
{
printf("括号合法");
}
else
{
printf("括号不合法");
}
}
中缀转后缀机算

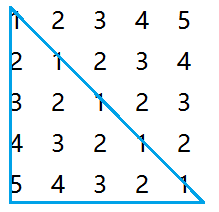
数组和特殊矩阵
核心思想:总=满+零
例如:i行j列元素有i-1行满和j个零。
对称矩阵
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
=================================
若以行优先进行:
对于矩阵a[i][j]压缩=>B[k],若i,j都从0开始
第1行 1个元素
第2行 2个元素
···
第i-1行 i-1个元素
第i行 i个元素
a[i][j]存储在B中第多少个位置分析如下:
第i行前有i-1行满的,满元素的行就有:
[1+(i-1)]*(i-1)/2=i(i-1)/2
再看元素所在行第几个
第j个从左往右数,所以是在第j个元素
总=i(i-1)/2+j [若下标从0开始,-1即可]
=================================
=================================
若以列优先进行:
对于矩阵a[i][j]压缩=>B[k],若i,j都从0开始
第1行 n个元素
第2行 n-1个元素
···
第j-1行 n-(j-1)+1=n-j+2个元素
第j行 n-j+1个元素 [每行减j个,少1个加回去]
a[i][j]存储在B中第多少个位置分析如下:
第j列前有j-1列满的,满元素的行就有:
[n+(n-j+2)](j-1)/2
再看元素所在列第几个
第i个从上往下数
第1列说5其实就是5,实际存了5个元素
第2列说5其实是4,实际存了4个元素
所以第i行说i其实是在第i-j+1个元素,实际存了i-j+1个元素
另外,j=i的时候是对角线上的元素,i-j为0,但对角线上的元素一定是第一个元素,所以+1,为什么是i-j而不是j-i呢?因为这里下半角矩阵i是≥j的
三角矩阵
三对角矩阵
树和二叉树
树的性质
- 树的节点数n等于所有结点的度总和+1。
- 度为m的树第i层最多有m的i-1次方个结点(i≥1)。
- 高度为h的m叉树最多节点树为:
1
2
3
4
5
6
第一行有m^0个
第二行有m^1个
第三行有m^2个
第四行有m^3个
第h行有m^h-1个
利用等比数列求和公式即可解出
- 度为m有n个结点的树最小高度是: \(\lceillog_m(n(m-1)+1)\rceil\)
加一向下取整就是直接向上取整。

- 具有n个结点、度为m的树最大高度是n-m+1。
- 高度为h、度为m的树最少有n+m-1个结点。
二叉树
- 非空二叉树叶子结点🍃的个数度为2的结点的个数+1。
- 完全二叉树的最后一个分支结点是${\lfloor}\frac{n}{2}{\rfloor}$
- 第i层最多有$2^{i-1}$个结点。
- n个结点最多有n+1个空指针。
- 满二叉树的结点数为:\(2^h-1\)
- n个节点最多有多少种形态
线索二叉树
- x结点的前驱后继:
| 中序线索二叉树 | 先序线索二叉树 | 后序线索二叉树 | |
|---|---|---|---|
| 前驱 | 左子树的最右下结点 | ✖ | 有右子树=>前驱是右子节点 无右子树=>前驱是左子节点 |
| 后继 | 右子树的最左下结点 | 有左子树,则后继是左子节点 没有左子树但有右子树,则是右子节点 如果左右子树都没有,则该节点是单节点或叶子节点。 |
✖ |

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
#include <stdio.h>
#include <stdlib.h>
typedef struct threadBitNode
{
char value;
struct threadBitNode *lchild;
struct threadBitNode *rchild;
int ltag;
int rtag;
} threadBitNode, *threadBitTree; // 分别定义二叉结点和二叉树
threadBitNode *pre = NULL;
void visit(threadBitNode *T)
{
// printf("值为:%c\n", T->value);
if (T->lchild == NULL)
{
T->lchild = pre;
T->ltag = 1;
if (pre != NULL)
printf("左线索化:%c=>%c\n", T->value, pre->value);
else
printf("左线索化:%c=>%c\n", T->value, pre);
}
if (pre != NULL && pre->rchild == NULL)
{
pre->rchild = T;
pre->rtag = 1;
printf("右线索化:%c=>%c\n", pre->value, T->value);
}
pre = T;
}
void inThread(threadBitTree T)
{
if (T != NULL)
{
inThread(T->lchild); // 遍历左子树
visit(T);
inThread(T->rchild); // 遍历右子树
}
}
threadBitNode *createNewNode(char v)
{
threadBitNode *newNode = (threadBitNode *)(malloc(sizeof(threadBitNode)));
newNode->value = v;
newNode->lchild = NULL;
newNode->rchild = NULL;
return newNode;
}
int main()
{
// 初始化二叉树
threadBitTree root = createNewNode('A');
root->lchild = createNewNode('B');
root->rchild = createNewNode('C');
root->lchild->lchild = createNewNode('D');
root->lchild->rchild = createNewNode('E');
root->lchild->lchild->rchild = createNewNode('G');
root->rchild->lchild = createNewNode('F');
inThread(root);
pre->rchild = NULL;
pre->rtag = 1;
printf("右线索化:%c=>%c\n", pre->value, NULL);
return 0;
}
图
无向图
-
无向图的边的取值范围是$0{\sim}\frac{n(n-1)}{2}$,因为每一条边都可以最多连接n-1,两两抵消除以2,最多边的情况下的无向图被称为完全图
- 无向图中的极大连通子图被称为连通分量(可以类比极大线性无关组)
- 所有顶点都连通的无向图被称为连通图,连通图最少有n-1条边,非连通图最多有$C^2_{n-1}$条边
有向图
- 有向图中的极大强连通子图被称为强连通分量
- 所有顶点都连通的有向图被称为强连通图,强连通图最少有n条边(形成回路)
简单图
拓扑排序:https://oi-wiki.org/graph/topo/
子图
- 并非所有的子集都可以构成子图,如果只有边而没有带上顶点那么就根本不满足图的概念
- 所有的顶点和边都属于图G的图称为G的子图。含有G的所有顶点的子图称为G的生成子图。
邻接矩阵法
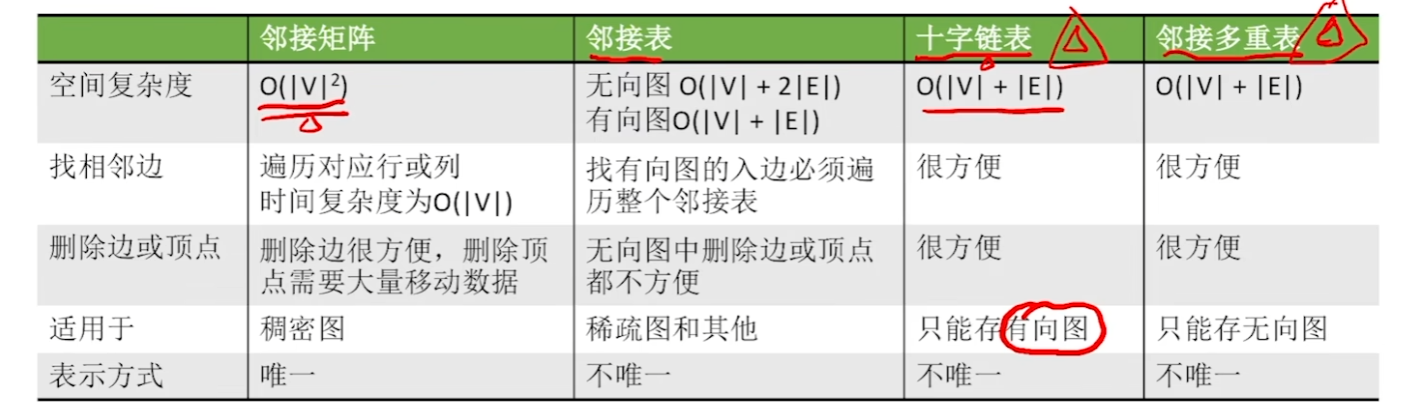

领接表

十字链表
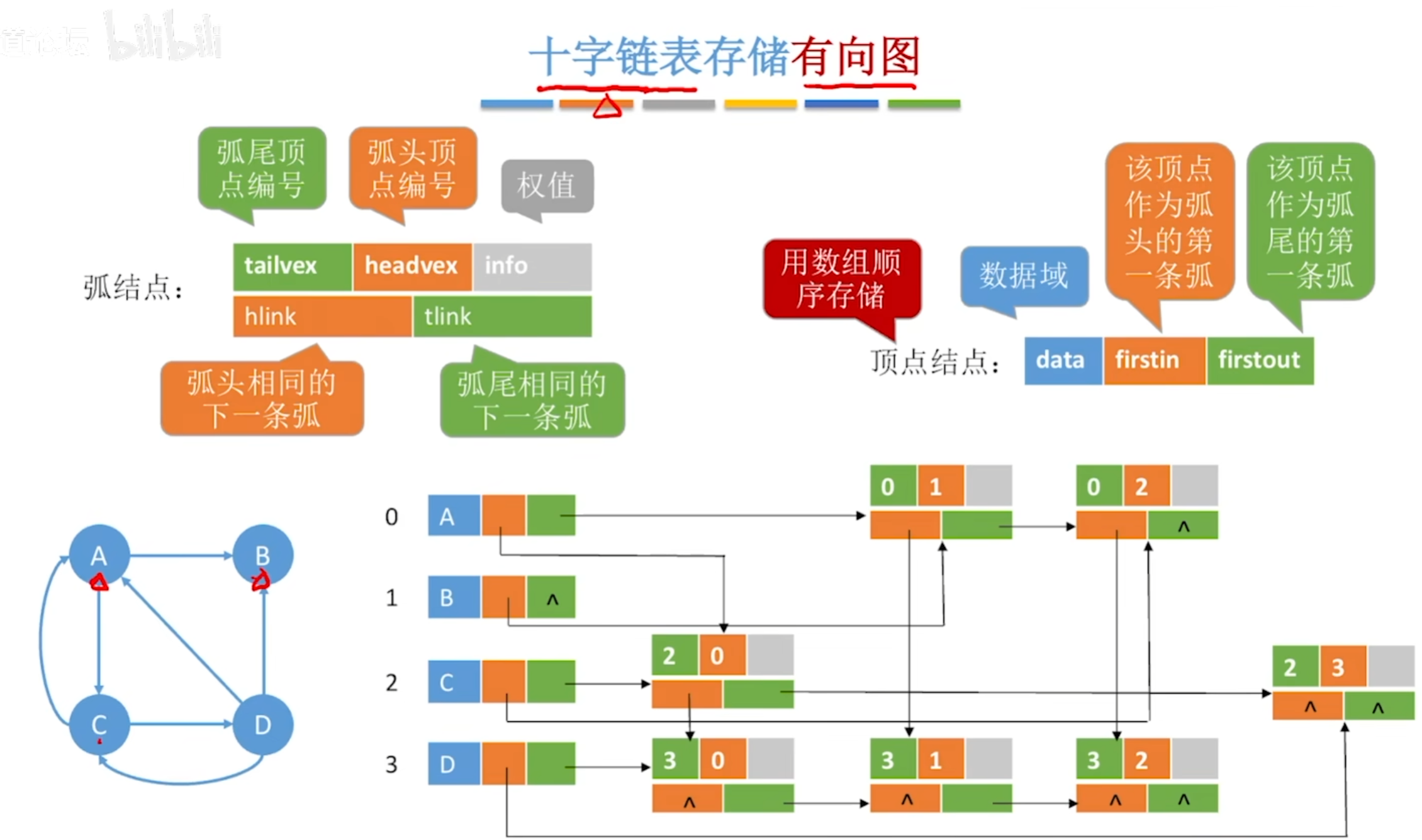
绿色指针本来就是要连接的,加一个橙色找入度。
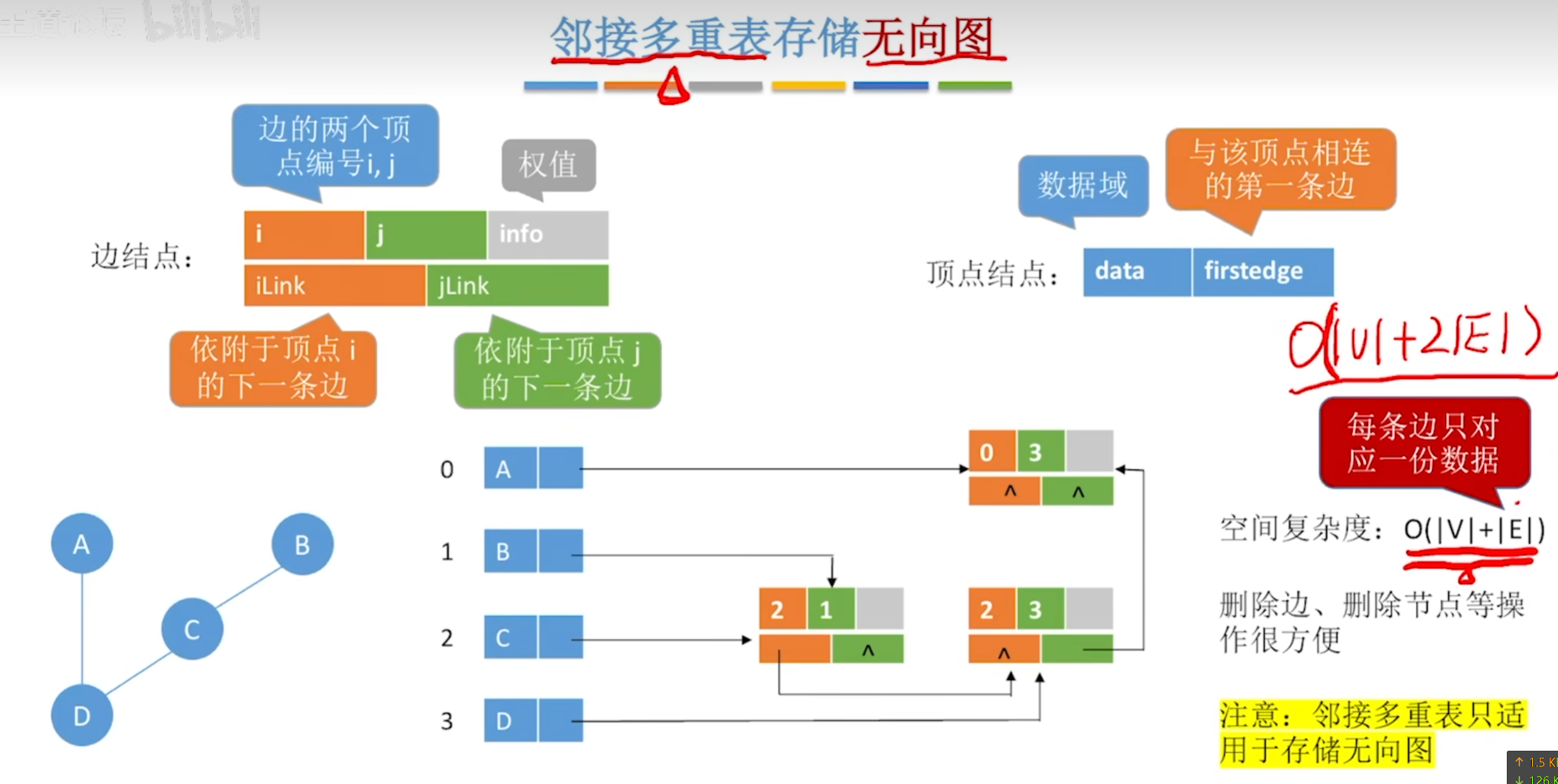
邻接多重表
邻接矩阵存储无向图的缺点:每条边对应两份冗余信息,删除顶点、删除边等操作时间复杂度高。
邻接表存储无向图的缺点:空间复杂度高。
图的基本操作
| 操作 | 邻接矩阵 | 领接表 |
|---|---|---|
| 判断是否存在边 | $O(1)$ | $O(1)-O(V)$ |
| 获取图G中边(x,y)或<x,y>对应的权值 | $O(1)$ | $O(1)-O(V)$ |
| 设置图G中边(x,y)或<x,y>对应的权值 | $O(1)$ | $O(1)-O(V)$ |
| 无向图列出图G中与结点x邻接的边 | 出$O(V)$ | $O(1)-O(V)$ |
| 有向图列出图G中与结点x邻接的边 | 遍历矩阵一行一列$O(V)$ | 入:遍历所有顶点找连到这个顶点的。出$O(1)-O(V)$ 入$O(E)$ |
| 无向图插入顶点x | 新增一行一列$O(1)$ | 加一个新结点$O(1)$ |
| 无向图删除顶点x | 删除这一行和这一列,标记为已删除。$O(V)$ | 删除这一个结点和后面连的关系链,标记为已删除。$O(1)-O(E)$ |
| 有向图删除顶点x | 删除这一行和这一列,标记为已删除。$O(V)$ | 删出边:删除这一个结点和后面连的关系链,标记为已删除。$O(1)-O(E)$ 删入边:删除这一个结点和后面连的关系链,标记为已删除。遍历所有顶点找到所有指向这个顶点的顶点删除。$O(E)$ |
| 无向图增加边 | $O(1)$ | $O(1)$ |
| 有向图增加边 | $O(1)$ | $O(1)$ |
| 无向图求图G中顶点x的第一个邻接点 | $O(1)-O(V)$ | $O(1)-O(V)$ |
| 有向图求图G中顶点x的第一个邻接点 | $O(1)-O(V)$ | 出:$O(1)$ 入:$O(1)-O(E)$ |
| 无向图假设图G中顶点y是顶点x的一个邻接点,返回除y之外顶点x的下一个邻接点的顶点号,若y是x的最后邻接点,则返回-1 | $O(1)-O(V)$ | $O(1)$ |
图的遍历
| 广度优先遍历(BFS) | 深度优先遍历(DFS) | |
|---|---|---|
| 时间复杂度 | 矩阵:$O(n+e)$ 表:$O(n^2)$ |
矩阵:$O(n+e)$ 表:$O(n^2)$ |
| 空间复杂度 | 矩阵:$O(n)$ 表:$O(n)$ |
矩阵:$O(n)$ 表:$O(n)$ |
| 对应树中 | 层序遍历 | 先序遍历(根左右) |
| 辅助数据结构 | 队列 | 栈 |
| 应用 | 单源最短路径 | 判断是否有环 |
| 🌳高 | 低 | 高 |
图的应用
最小生成树
各个算法
| Prim算法(加点法) | Kruskal算法(加边法) | |
|---|---|---|
| 步骤 | 从一个顶点开始构建生成树,依次将权值最小的顶点加入生成树,直到所有顶点都加入。 | 写出所有顶点,依次选择一条权值最小的边,使这条边的两头连通,直到所有结点都连通。 |
| 时间复杂度 | $O(n^2)$ | $O(Elog_2E)$ |
性质
- 边数小于 n-1,不存在最小生成树。边数等于 n-1,唯一为图本身。边数大于n-1,生成树不唯一。
- 若最小生成树不唯一,则一定存在权值相等的边。当图的各边的权值互不相等时,图的最小生成树是唯一的。
- 最小生成树可能不唯一,但代价一定相同。
最短路径问题
各个算法
| BFS算法 | Dijkstra算法 | Floyd算法 | |
|---|---|---|---|
| 用途 | 单源最短路径 | 单源最短路径(也可以两顶点) | 双源最短路径 |
| 无权图 | 适用 | 适用 | 适用 |
| 有权图 | 不适用 | 适用 | 适用 |
| 带负权图 | 不适用 | 不适用 | 适用 |
| 带负回路图 | 不适用 | 不适用 | 不适用 |
| 时间复杂度 | $O(n^2)$或$O(n+E)$ | $O(n^2)$ | $O(n^3)$ |
-
BFS算法
说明 V1 V3 V4 V5 V6 V7 V8 V9 V10 dist数组 最短路径长度 path数组 前驱节点 选择一个源节点,将其路径设为0,按广度优先顺序依次访问节点,修改路径长度为上一个节点+1,并将前驱节点填入。
-
Dijkstra算法
说明 V1 V3 V4 V5 V6 V7 V8 V9 V10 Final数组 标记是否为最短路径 是 dist数组 最短路径长度 0 path数组 前驱节点 -1 选择一个源节点,标记final为是,然后在不是最短路径的里面找dist最小的,依次加到其余节点上,看是否比原来的值小,同时修改前驱。循环剩余不是最短路径的节点。
-
Floyd算法
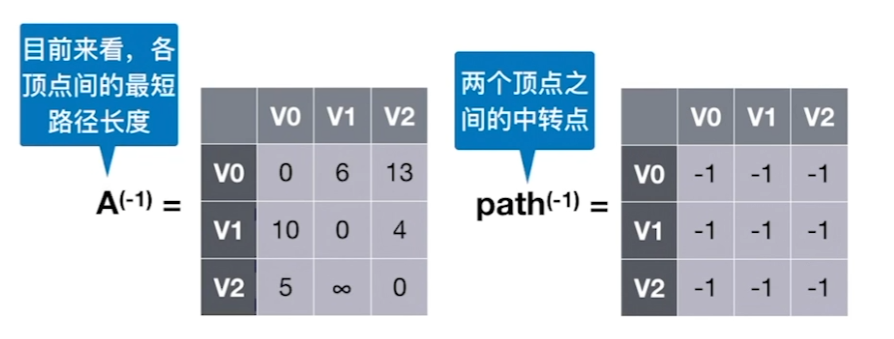
A矩阵:行坐标通过某个点到列坐标的距离
path:行坐标到列坐标最短路径应该的前驱
写出不通过任何点两两点之间的距离,依次通过前一个表判断从各个点中转的距离,判断是否比原来的值小,如果小的话,更新最短路径并更新最短路径前驱。
性质
- 求解最短路径允许有环路的出现。
有向无环图描述表达式
- 写出不重复的各个节点
- 按运算顺序为运算符编上序号
- ➕同层,✖️上层
拓扑排序
拓扑排序求法
依次找到入度为零的点,写出来之后删掉这个点和边。
性质
- 对于任一有向图,若它的邻接矩阵为上三角或下三角,则一定存在拓扑序列(可能不唯一)。反之,若图存在拓扑序列,却不一定能满足邻接矩阵中主对角线以下的元素均为零,但是可以通过适当地调整结点编号,使其邻接矩阵满足前述性质。
- 在拓扑排序算法中为暂存入度为零的顶点,可以使用栈,也可以使用队列,因为顺序随便。
AOE网和关键路径
关键路径的求法
AOE网是一个【有向无环图】,关键路径也就是最长路径。
【图-AOE网和关键路径】 https://www.bilibili.com/video/BV1dy421a7S1?t=659.3
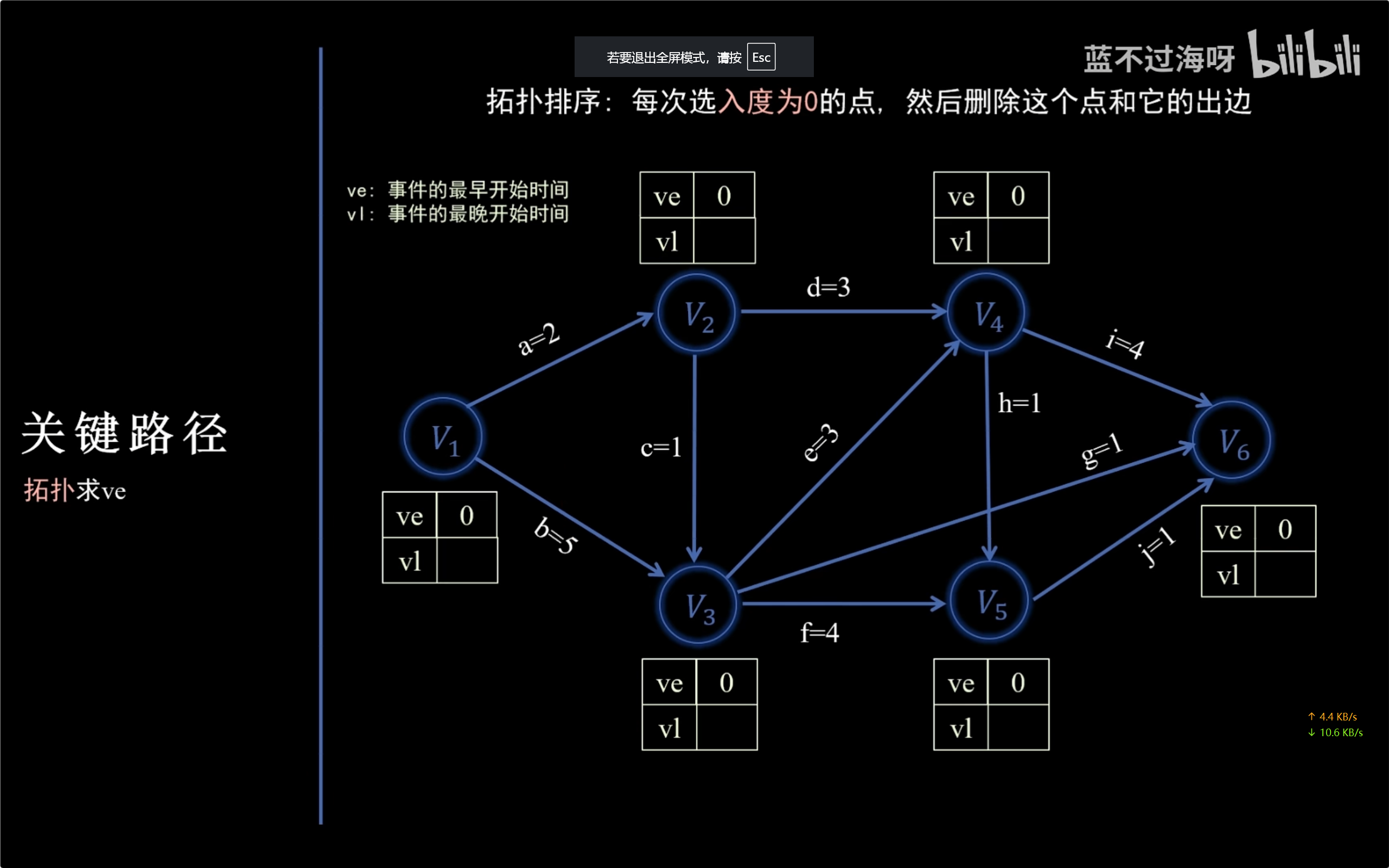
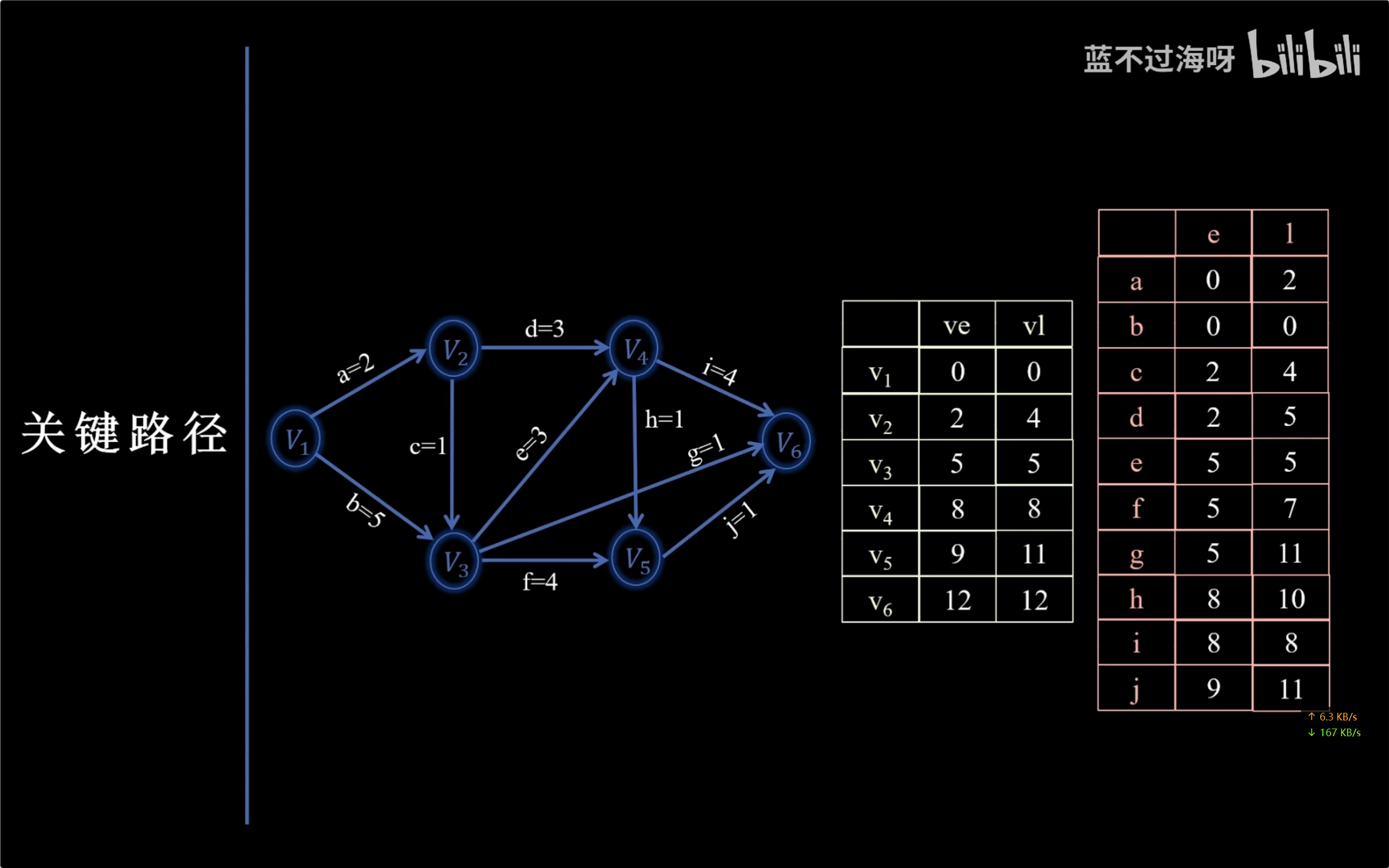
先求点:正向拓扑排序找最大的是最早开始时间,再逆向逆拓扑排序找最小的是最晚开始时间。
再求边:边最早就是边起点最早,边最晚就是边终点最晚减边耗时。
最早和最晚时间一样的是关键路径。
性质
- 改变所有关键路径的公共部分不一定影响关键路径,只有缩短才会缩短工期。
- 关键路径上的活动延长多少,工期就随之延长多少 。
查找
基本概念
平均查找长度
查找概率✖️查找次数
线性结构
| 要求 | 时间复杂度 | ASL | |
|---|---|---|---|
| 顺序查找 | $\frac{n+1}{2}$(一般) $\frac{n}{2}+\frac{n}{n+1}$(有序) |
||
| 折半查找 | 必须是数组 必须有序 |
$O(log_2n)$ | $log_2(n+1)-1$ |
折半查找
性能分析
查找成功的平均查找长度:$((n+1)/n)*(log(n+1)-1)$
查找失败的最多比较次数:$\lceillog_2(n+1)\rceil$
查找失败的最少比较次数:$\lceillog_2(n+1)\rceil-1$因为平衡二叉树最多相差1
注意点
- 表必须有序而且必须是顺序存储结构
二叉判定树
二叉判定树是用来分析折半查找而设计的二叉树
- 二叉判定树是一颗平衡二叉树
- 二叉判定树的最高度是$\lceillog_2(n+1)\rceil$
- 向下取整左多等、向上取整左少等
- 有n个非叶节点和n+1个方形虚拟节点
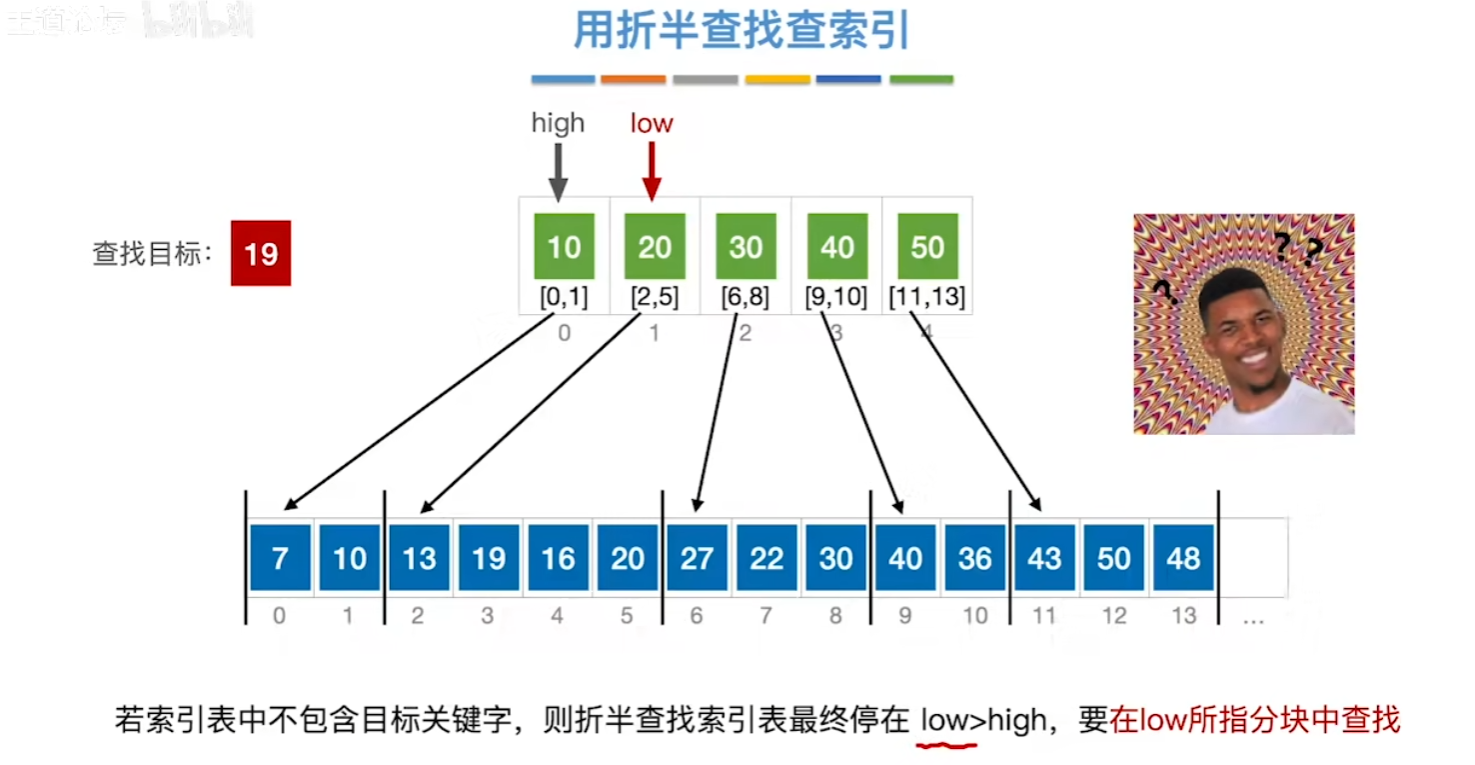
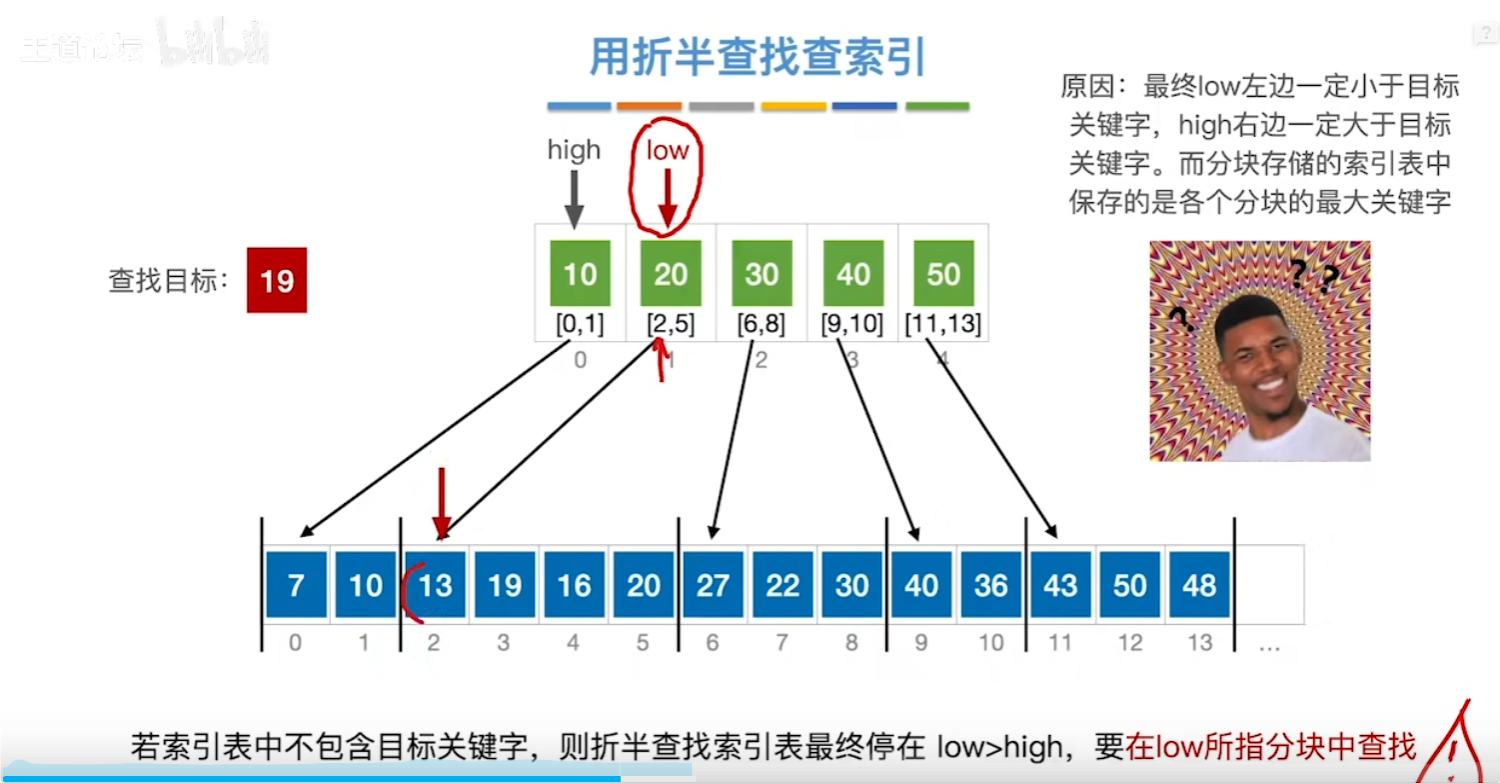
分块查找
易错点
对索引表进行折半查找时,若索引表中不包含目标关键字,则折半查找最终停在low>high,要在low所指分块中查找。
查找效率分析
| 查索引 | 查块内 | 查索引 | 查块内 | ASL=查索引➕查分块 |
|---|---|---|---|---|
| 顺序 | 顺序 | $\frac{b+1}{2}$ | $\frac{s+1}{2}$ | $ASL=\frac{b+1}{2}+\frac{s+1}{2}=\frac{s^2+2s+n}{2s},当s=\sqrt{n}时,ASL_{min}=\sqrt{n}+1$ |
| 折半 | 顺序 | $\lceillog_2(b+1)\rceil$ | $\frac{s+1}{2}$ | $ASL=\lceillog_2(b+1)\rceil+\frac{s+1}{2}$ |
树形结构
二叉排序树(BST)(二叉搜索树、二叉查找树)
二叉排序树的删除
| 删除 | 删除操作 |
|---|---|
| 叶子节点 | 直接删除 |
| 有左子树 | 删除后将其左子树接到上一层 |
| 有右子树 | 删除后将其右子树接到上一层 |
| 有左右子树 | 删除后将其左子树最大或右子树最小接到上一层 |
二叉排序树效率
平衡二叉树VS红黑树
旋转次数
| 树 | 插入 | 删除 |
|---|---|---|
| AVL | 最多两次(双旋) | 最多树高($log_2n$)次 |
| 红黑树 | 最多两次(双旋) | 最多三次 |
性能分析
| 树 | 查找效率 | 插入效率 | 删除效率 |
|---|---|---|---|
| 平衡二叉树 | $O(log_2n)$ | $O(log_2n)$ | $O(log_2n)$ |
| 红黑树 | $O(log_2n)$ | $O(log_2n)$ | $O(log_2n)$ |
- 树高就是查询效率,因此AVL的查询效率往往更优
平衡二叉树(AVL)
平衡因子
左子树高度-右子树高度的绝对值小于1,平衡因子均为1,即平衡二叉树满足平衡的最少结点情况
性质
当按关键字有序的顺序插入初始为空的平衡二叉树时,若关键字个数$n=2^k-1$时,则该平衡二叉树一定是一棵满二叉树。
深度为i的平衡二叉树最少有多少个结点?
公式:$ 对于 n \geq 3,有f(n) = f(n-1) + f(n-2) + 1 ,且f(1)=1和f(2)=2$
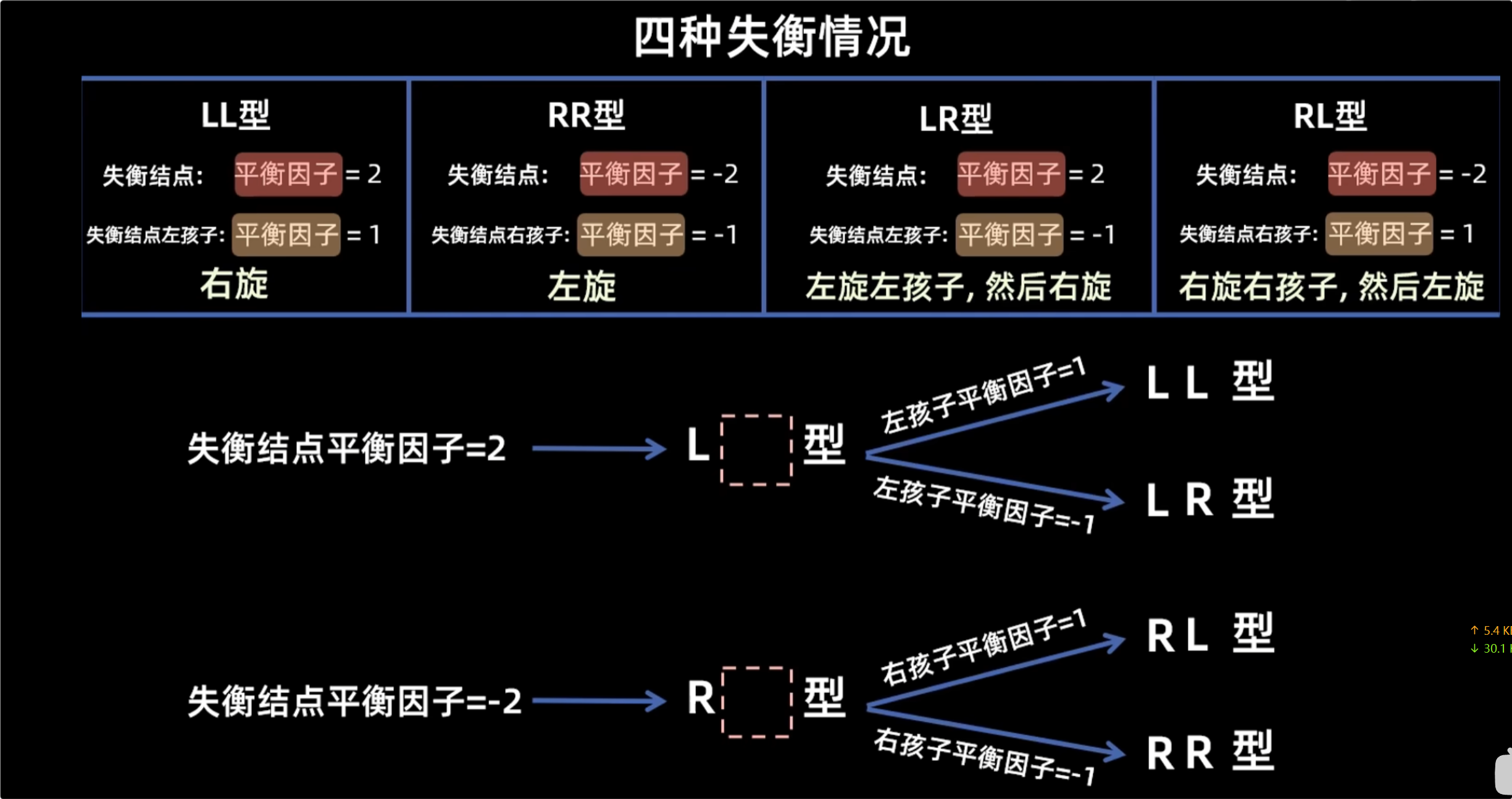
插入操作
小技巧:从下往上找最小的不平衡的二叉树,在这棵子树从根往下找三个提出来,成为一颗新的树
红黑树
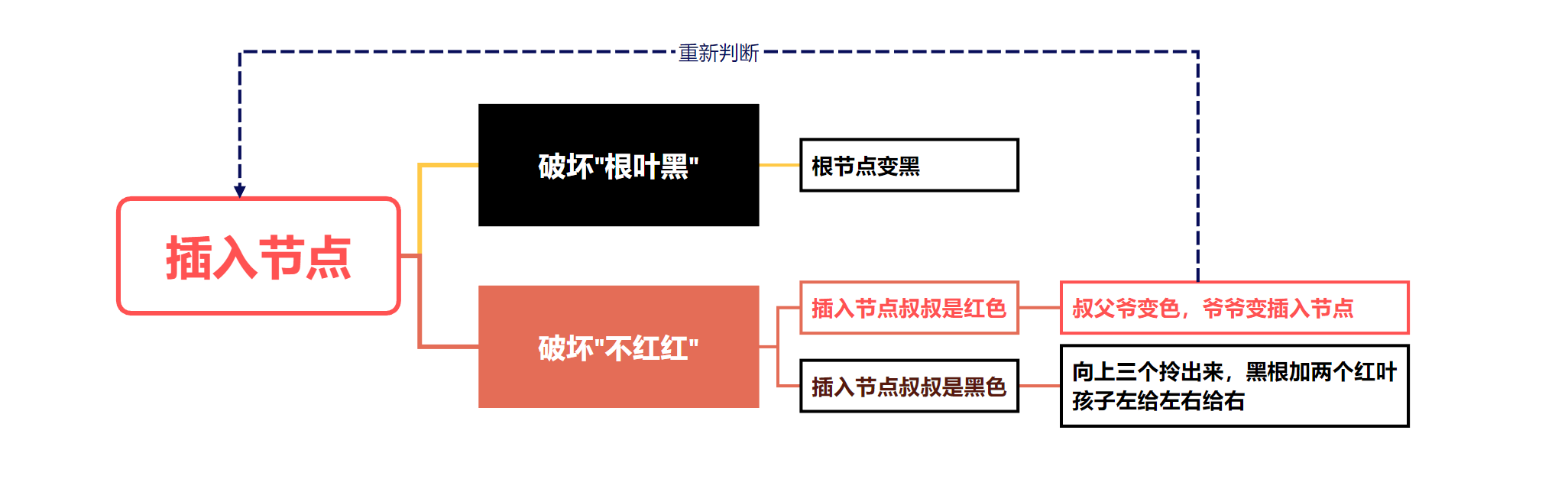
性质
| 左根右 | 二叉排序树(不一定要平衡) |
| 根叶黑 | 根节点和叶子节点都是黑色 |
| 不红红 | 没有连续的两个红色节点 |
| 黑路同 | 任意节点到叶子节点路径上黑色节点数量相同 |
- 红黑树的红结点数最大可以是黑结点数的2倍。
- 红黑树的任意一个结点的左右子树高度(含叶结点)之比不超过2。
- 若所有节点都是黑色的,那么他一定是一颗满二叉树(黑路同,故路都是相同节点)
- 一棵含有n个结点的红黑树的高度至多为$2log_2(n +1)$
插入操作
二叉树的演变
B树
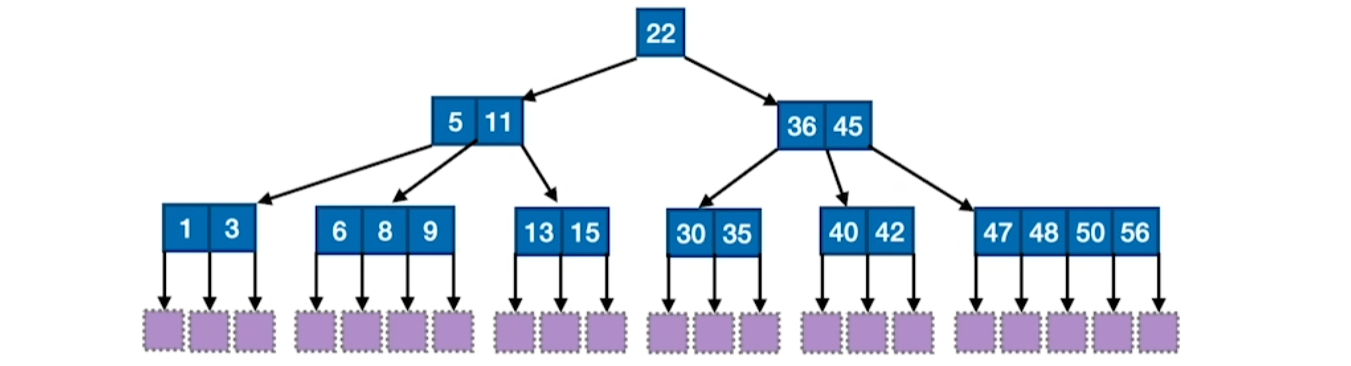
B树的插入
出现上溢出中间( $\lceil\frac{m}{2}\rceil$)元素上去,两边分开
B树的删除
性质
- 每个节点最多m个关键字,m+1个分叉
- 如果根节点不是终端节点,那么这个节点至少有两个子树
- n个关键字的B树必有n+1个叶子节点
| 最少 | 最多 | |
|---|---|---|
| n个节点的m阶B树的高度 | $log_m(n+1)$ | $log_{\lceil\frac{m}{2}\rceil}\frac{(n+1)}{2}+1$ |
| 某个节点的子树数 | $\lceil\frac{m}{2}\rceil$ | m |
| 某个节点的关键字数 | $\lceil\frac{m}{2}\rceil-1$ | m-1 |
| 高度为h的m阶B树关键字数 | $m^h-1$ | |
| 高度为h的m阶B树叶子节点数 | $2(\lceil\frac{m}{2}\rceil)^{h-1}$ |
分层分析
| 层数 | 结点min | 结点MAX | 分叉min | 分叉MAX | 结点关键字min | 结点关键字MAX |
|---|---|---|---|---|---|---|
| 第1层 | 1 | 1 | 2 | m | 1 | m-1 |
| 第2层 | 2 | $m$ | $\lceil\frac{m}{2}\rceil$ | m | $\lceil\frac{m}{2}\rceil-1$ | m-1 |
| 第3层 | $2\lceil\frac{m}{2}\rceil$ | $m^2$ | $\lceil\frac{m}{2}\rceil$ | m | $\lceil\frac{m}{2}\rceil-1$ | m-1 |
| 第4层 | $2\lceil\frac{m}{2}\rceil^2$ | $m^3$ | $\lceil\frac{m}{2}\rceil$ | m | $\lceil\frac{m}{2}\rceil-1$ | m-1 |
| ··· | ··· | ··· | ··· | ··· | ··· | ··· |
| 第h层 | $2\lceil\frac{m}{2}\rceil^{h-2}$ | $m^{h-1}$ | $\lceil\frac{m}{2}\rceil$ | m | $\lceil\frac{m}{2}\rceil-1$ | m-1 |
| 第h+1层 | $2\lceil\frac{m}{2}\rceil^{h-1}$ | $m^{h}$ | $\lceil\frac{m}{2}\rceil$ | m | $\lceil\frac{m}{2}\rceil-1$ | m-1 |
-
结点min=上层节点最少✖️上层分叉最少(上层的每个分叉都对于本层的一个节点)
-
总关键字最多=SUM(节点最多+节点关键字最多)=$m^h-1$
-
n个非叶节点的m阶B树关键字最少$(n-1)(\lceil\frac{m}{2}\rceil-1)+1$
B➕树
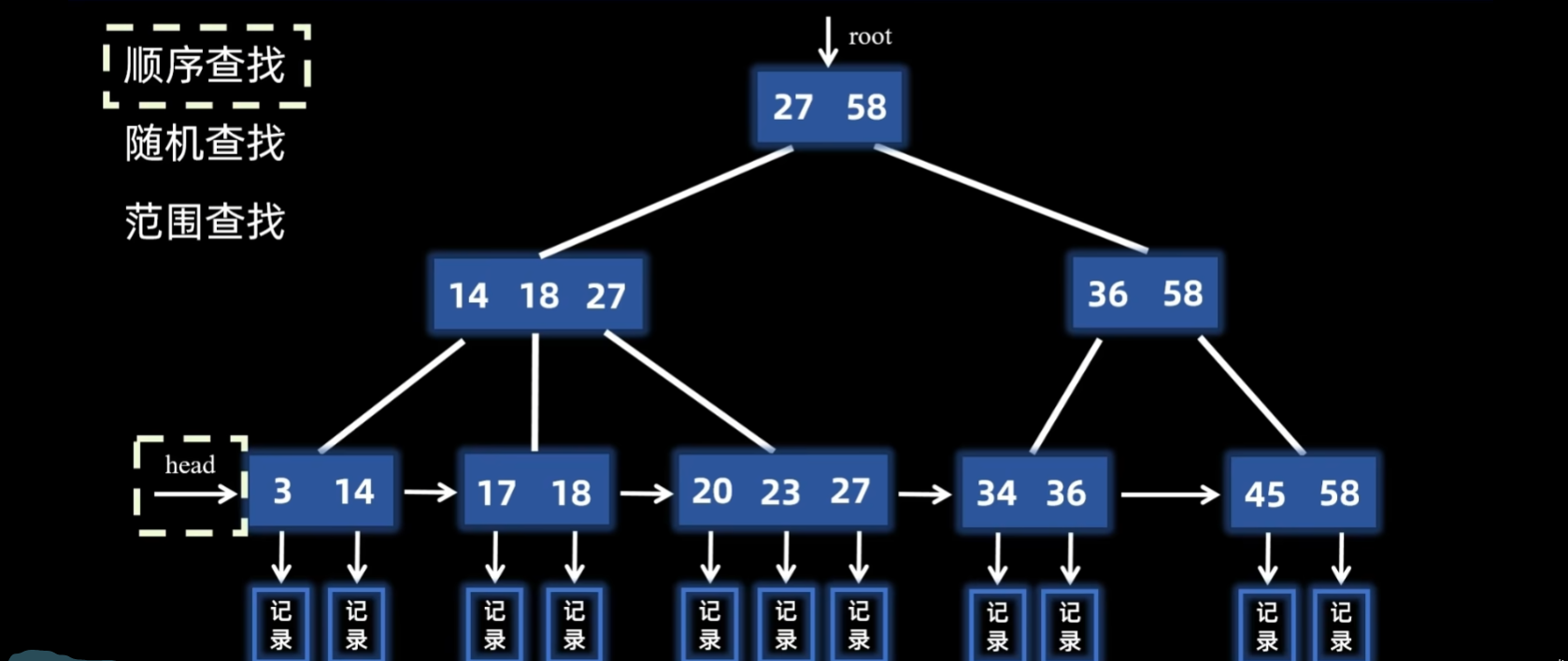
性质
- m个分支节点最多有m个子树
- 终端节点包含所有的数据,非叶节点只索引
散列查找
基本概念
- 装填因子a=表中记录个数/散列表表长
常见散列函数
| 方法 | ||
|---|---|---|
| 除留余数法 | H(key)=key %p,p是不大于表长的质数 | |
| 直接定址法 | H(key)=key或H(key)=akey) = akey + b | |
| 数字分析法 | 选取数码分布较为均匀的若干位作为散列地址 | |
| 平方取中法 | 取关键字的平方值的中间几位作为散列地址 |
处理冲突
拉链法
使用链表连接起来
开放定址法
| 方法 | 步长 | 备注 |
|---|---|---|
| 线性探测法 | $0、1、2、3···m-1$ | |
| 平方探测法 | $0^2、1^2、-1^2、2^2、-2^2···k^2、-k^2$ | 散列表长度m必须是一个可以表示成4x+3的素数,才能探测到到所有位置 |
| 伪随机序列法 | 随机序列 |
开放定址法不能简单的删除
再散列法
准备多个散列函数,冲突了就使用下一个
排序
概念
时间复杂度
基于比较的算法时间复杂度最低是$nlog_2n$
分类

对比
| 算法 | 算法理解 | 算法演练 | 比较次数最好 | 比较次数最坏 | 交换次数 | 存储 | 时间复杂度最好 | 时间复杂度最坏 | 时间复杂度平均 | 空间复杂度平均 | 移动次数 | 稳定性 | 每趟是否可以确定 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 快速排序 | 挖坑填数 | 顺 | $O(n·log_2n)$ | $O(n^2)$ | $O(n·log_2n)$ | $O(log_2n)-O(n)$ | 不稳 | 是(中枢) | 基准元素有序 | ||||||
| 归并排序(无关) | 合并多路有序数组 | 第一次归并:合并两个长度为1的数组,总共有n/2个合并,比较次数为n/2。 第二次归并:合并两个长度为2的数组,最少比较次数是2,最多是3,总共有n/4次,比较次数是(2~3)n/4。 第三次归并:合并两个长度为4的数组,最少比较次数是4,最多是7,总共有n/8次合并,比较次数是(4-7)n/8。 |
顺链 | $O(n·log_2n)$ | $O(n·log_2n)$ | $O(n·log_2n)$ | $O(n)$ | 稳 | 不能 | ||||||
| 直接插入排序 | 假定前面i个元素已经排好,接下来将第(i+1)个元素插入到前面的序列中 | $n-1$ | $\frac{n(n-1)}{2}$ | 顺链 | $O(n)$ | $O(n^2)$ | $O(n^2)$ | $O(1)$ | 稳 | 是 | 第i趟前i+1个有序 | (基本有序快) | |||
| 折半插入排序 | 假定前面i个元素已经排好,接下来将第(i+1)个元素插入到前面的序列中 | $n-1$ | $\frac{n(n-1)}{2}$ | 0—$\frac{n(n-1)}{2}$ | 顺 | $O(n)$ | $O(n^2)$ | $O(n^2)$ | $O(1)$ | 稳 | 是 | 第i趟前i+1个有序 | |||
| 冒泡交换排序 | 冒泡泡一样,相邻两个元素相比。 | 第一次对于n个元素,两两比较需要n-1次,确定出一个最值元素,下一次n-1个元素两两比较需要n-2次,以此类推。 | $n-1$ | $\frac{n(n-1)}{2}$ | 0—$n^2$(逆序数) | 顺链 | $O(n)$ | $O(n^2)$ | $O(n^2)$ | $O(1)$ | $O(n)$ | 稳 | 是 | (基本有序快) | |
| 简单选择排序(无关) | 每回合找出最小元素,然后交换到前面位置。 | 对于n个元素的序列,找出最小元素需要比较(n-1)次。第一回合后,序列只剩下(n-1)个元素,下一次找最小元素还需要(n-2)次比较。最后直到2个元素需要比较1次。 每一回合最多交换一次,有(n-1)回合,所以最多交换次数为(n-1),而且不比到最后一个无法确定是不是最小的,所以比较次数是固定的。 | $\frac{n(n-1)}{2}$ | $\frac{n(n-1)}{2}$ | $n-1$ | 顺链 | $O(n^2)$ | $O(n^2)$ | $O(n^2)$ | $O(1)$ | $O(n)$ | 是 | |||
| 希尔插入排序 | 希尔排序将序列划分成多个子序列,先对子序列分别排序,然后减少子序列个数,重复该过程。 | 希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。 | 顺 | $O(n)$ | $O(n^2)$ | $O(n^{1.3})$ | $O(1)$ | 不稳 | |||||||
| 堆排序 | 建立最小堆,然后依次取堆顶元素、删除和调整堆。 | 顺 | $O(n·log_2n)$ | $O(n·log_2n)$ | $O(n·log_2n)$ | $O(1)$ | 不稳 | 是 | |||||||
| 基数排序 | 基数排序根据多个键值对序列进行分配,属于分配类算法。 | 顺链 | $O(d*(n+r))$ | $O(d*(n+r))$ | $O(d*(n+r))$ | $O(r)$ | 稳 | 不能 | |||||||
| 计数排序(无关) | $O(n+k)$ | $O(k)$ |
比较次数

各个排序
直接插入排序
- 最坏情况下需要比较的次数是$\frac{n(n-1)}{2}$
- 最好情况下需要比较的次数是n-1
- 基本有序的情况下效率最高
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include <stdio.h>
void insertSort(int a[], int len)
{
int i, j, t;
for (i = 1; i < len; i++)
{
// 对比是否小于前面的值
if (a[i] < a[i - 1])
{
t = a[i];
for (j = i - 1; j >= 0 && t < a[j]; j--)
{
a[j + 1] = a[j];
}
a[j + 1] = t;
}
}
}
void main()
{
int a[10] = {5, 2, 1, 4, 3, 6, 7, 8, 9, 10};
int len = 10;
insertSort(a, len);
printf("排序后:\n");
for (int i = 0; i < len; i++)
printf("%d ", a[i]);
}
折半插入排序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
void binaryInsertSort(int a[], int len)
{
int i, j, t, left, right, mid;
left = 0;
for (i = 1; i < len; i++)
{
t = a[i];
left = 0;
right = i - 1;
while (left <= right)
{
mid = (left + right) / 2;
if (a[mid] > t)
right = mid - 1;
else
left = mid + 1;
}
for(j = i; j > left; j--)
a[j] = a[j - 1];
a[left] = t;
}
}
void main()
{
int a[10] = {5, 2, 1, 4, 3, 6, 7, 8, 9, 10};
int len = 10;
binaryInsertSort(a, len);
printf("排序后:\n");
for (int i = 0; i < len; i++)
printf("%d ", a[i]);
}
希尔排序
- 比较次数就是1+前面比他大的个数
冒泡排序
- 比较的次数就是两两相比逆序的个数
堆排序
| 建堆 | ||
- 建堆的时间复杂度是O(n)
- 建堆关键字对比次数不超过4n
| 下标 | 左孩子 | 右孩子 | 父节点 | 分支节点 | 叶子节点 |
|---|---|---|---|---|---|
| i | (i-1)/2 | i*2+1 | i*2+2 | i<=n/2 | i>n/2 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
#include <stdio.h>
void heapify(int arr[], int len, int i)
{
int largest = i;
int left = 2 * i + 1;
int right = 2 * i + 2;
if (left < len && arr[left] > arr[largest])
largest = left;
if (right < len && arr[right] > arr[largest])
largest = right;
if (largest != i)
{
int temp = arr[i];
arr[i] = arr[largest];
arr[largest] = temp;
heapify(arr, len, largest);
}
}
void heap_sort(int arr[], int len)
{
// 建堆
int i;
for (i = (len - 2) / 2; i >= 0; i--)
heapify(arr, len, i);
// 排序
for (i = len - 1; i > 0; i--)
{
int temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
heapify(arr, i, 0);
}
}
void main()
{
int arr[] = {12, 11, 13, 5, 6, 7};
int len = sizeof(arr) / sizeof(arr[0]);
heap_sort(arr, len);
for (int i = 0; i < len; i++)
printf("%d ", arr[i]);
}
快速排序
- 枢纽两边不可能出现又比枢纽大又比枢纽小的数,同时枢纽两边不可能都比枢纽大或都比枢纽小
- 快速排序的最好情况是每次划分将待排序列划分为等长的两部分。第一趟将第1个元素与后面的元素进行比较
简单选择排序
归并排序
先分段,再进行归并
- n个元素k路排序,躺数是$\lceillog_kn\rceil$
基数排序
- 适用于可以拆成d组
- 每组取值范围不大
- 数据元素n较大
总结
| 描述 | 算法 |
|---|---|
| 用到了随机存取的特性(换为链式存储会变慢) | 希、堆 |
| 可以并行执行 | 快、堆 |
| 排序趟数与原始状态无关 | 简、插、基(检查鸡官来了,谁来了都不好使) |
| 稳定排序 | 归、插、基、冒(稳定的龟插鸡毛) |
| 平均时间复杂度为$O(nlog_2n)$ | 归、堆、快(速度快就得归队快) |
| 能达到线性复杂度的 | 归、冒(毛龟) |
- 简单选择排序的移动次数很少,只需要找出最值交换即可
- 简单选择排序的总比较次数是确定的
外部排序
败者树
归并数
归并数的带权路径长度就是磁盘IO的次数,所以要让磁盘IO最小,就是构建哈夫曼树。